
[Hadoop] Basics of MapReduce Algorithms
Different Tasks in MapReduce Algorithms:
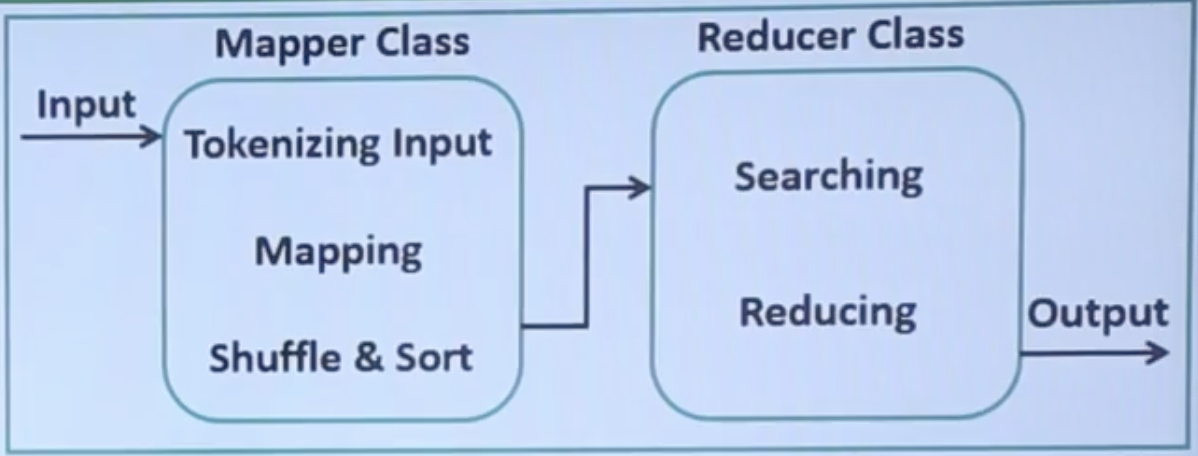
- The MapReduce progrmas have two tasks, the Map task and the Reduce task. The Map task is done by the Mapper Class, and Reduce Task is done by Reducer Class.
- Mapper class takes the input, tokenizes it, maps and sorts it. The output of Mapper class is used as input by Reducer class, which in turn searches matching pairs and reduces them.
MapReduce Task Example:
- One of the most fundamental MapReduce examples is Word Count problem. It takes the string with different words as input and counts the number of words of each type. Let’s see how the Mapper class and Reducer Class work for this task
- The mapper class tokenize the strings and make a sorted list of the words. it marks the words as keys and a number as value.
- The Reducer class takes the list and count the number of entries of each word. Finally creates another list with keys and their count values.
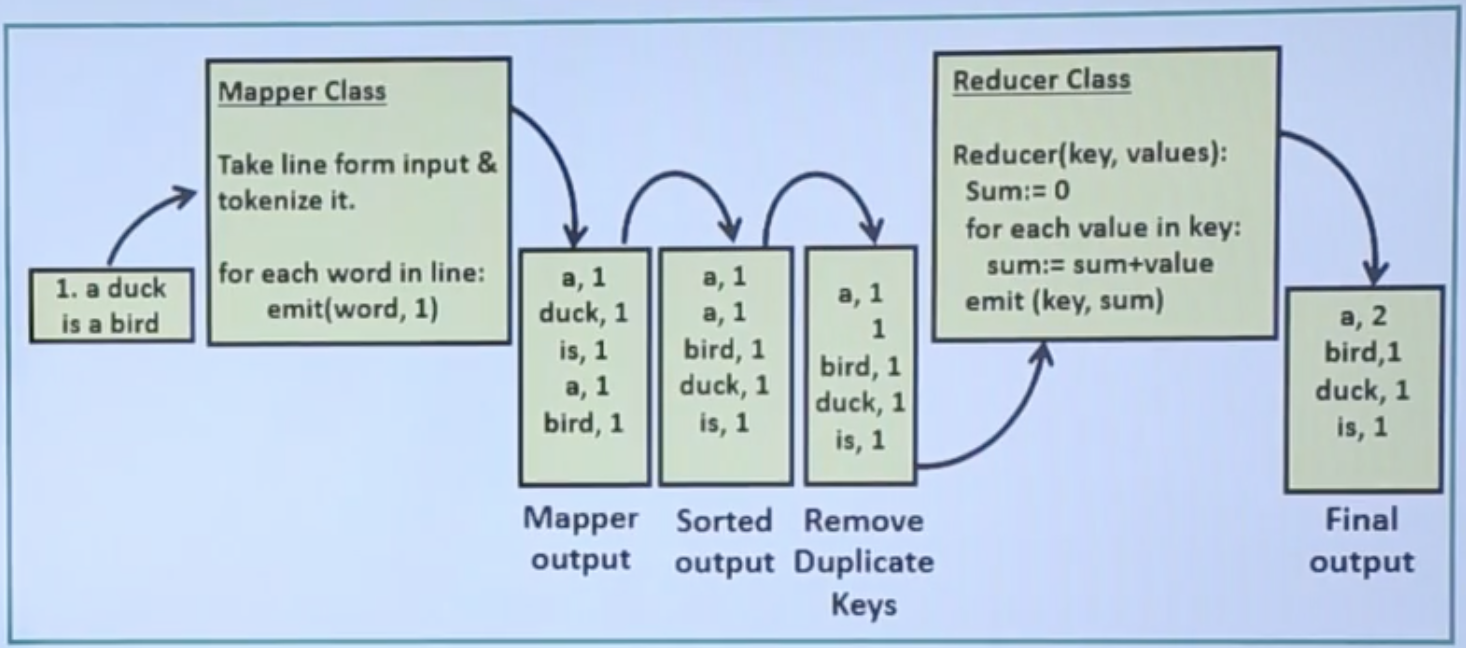
- Let the string is “a duck is a bird”. It has five words. This input is given as input of the Mapper class. Mapper will generate Key-Value pairs. After that reducer takes it as input, and find final word count output.

댓글남기기