
[Hadoop] HDFS Architecture
What is HDFS Architecture?
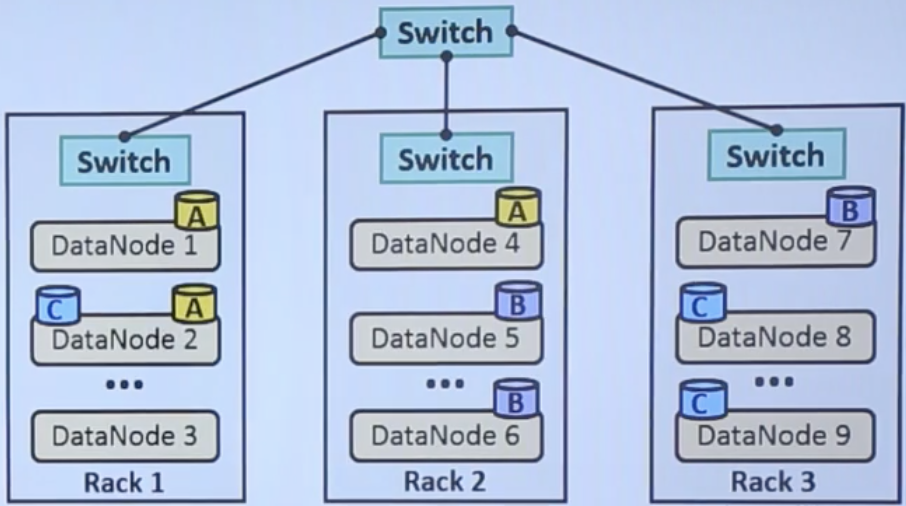
- Hadoop Distributed File System (HDFS) is like Master-Worker architecture. The master is the NameNode and the workers are the low-cost commodity hardware. In the DataNodes, the actual data is stored. In this architecture, there is single NameNode and multiple DataNodes.

What is the task of NameNode?
- The NameNode is used to store the meta-data and another data related for DataNodes. The NameNode also reponsible for:
- Managing the file-system namespace
- It controls the access of different clients into the data blocks.
- Periodically checks the availablility of the DataNodes.
- It also care about the replication factor of the data blocks.
What is the task of DataNodes?
- DataNodes are the main storage of data. Hadoop uses low-cost hardware to store data.
- DataNodes are responsible for storing, replication creatiing, deleting these type of jobs according to the instruction of NameNode.
- These DataNodes send the health report to the NameNode periodically. The default time is 3 seconds. So after every 3 seconds, these send the report to the NameNode.
What is the Secondary NameNode?
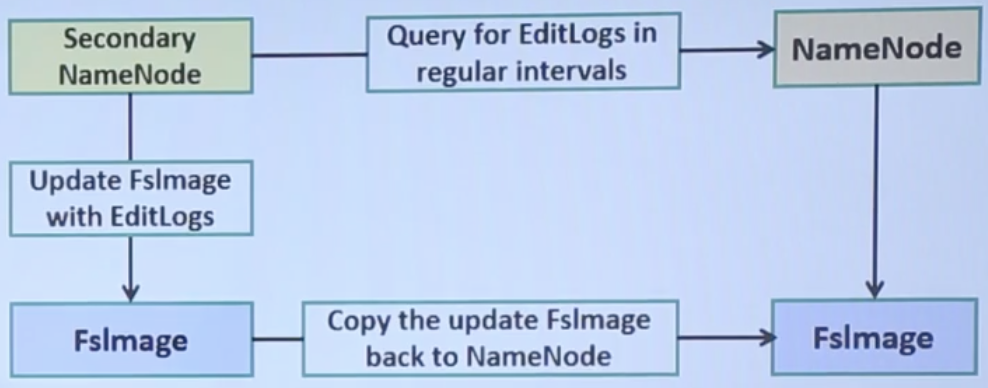
- Secondary NameNode: The Secondary NameNode is another specially dedicated node, which is used to take the checkpoints of the file-system. The Secondary NameNode is not the substitute of the Primary NameNode. It helps the NameNode but not replace for NameNode.

댓글남기기