
[Hadoop] Job Scheduling in MapReduce
How does the Job Scheduling Work?
- In Hadoop, different clients send their jobs to perform. The jobs are managed by the JobTracker or Resource Manager.
- There are three different Scheduling Schemes:
- First In First Out (FIFO) Scheduler
- Capacity Scheduler
- Fiar Scheduler
- The JobTracker comes with these three scheduling techniques, and the default is the FIFO. The Resource Manager takes Capacity Scheduler and Fair Scheduler, where the Capacity Scheduler is default.
How FIFO Scheduler Works?
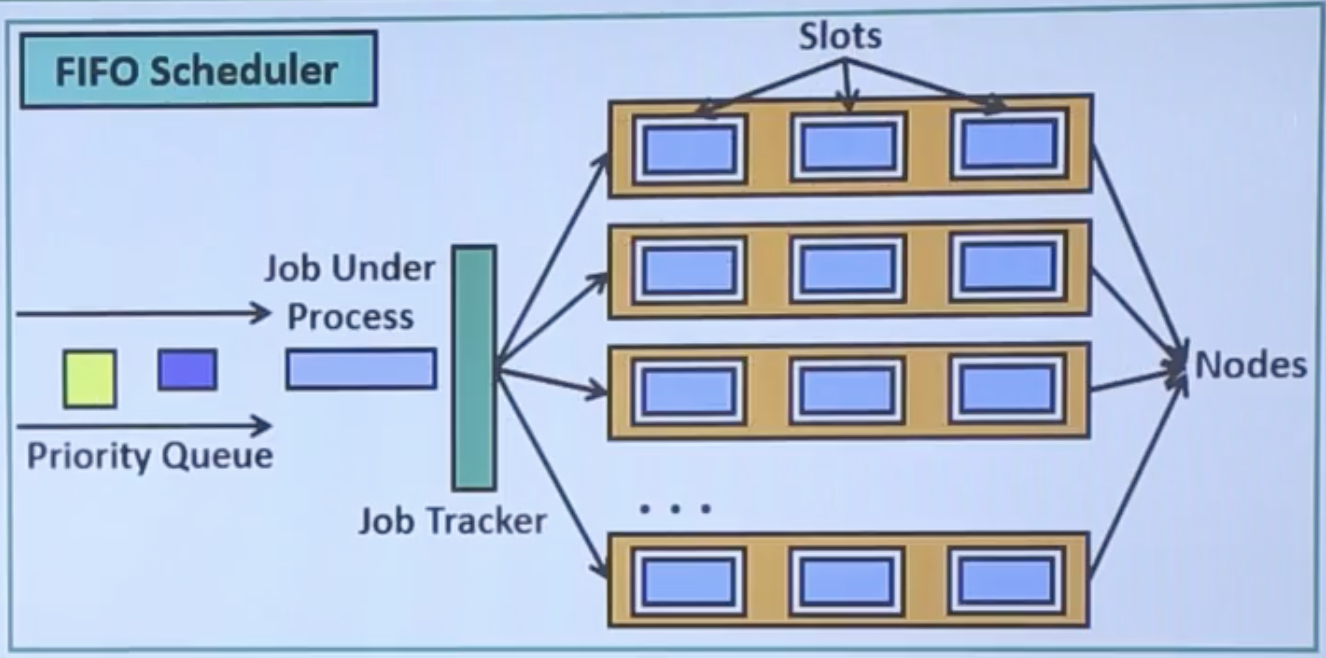
- The jobs are queued in the priority queue, and send it to the JobTracker. When a job is scheduled, even it’s priority is lower, no preemtion is allowed. So some higher prioriy process may wait for long time.
How Capacity Scheduler Works?
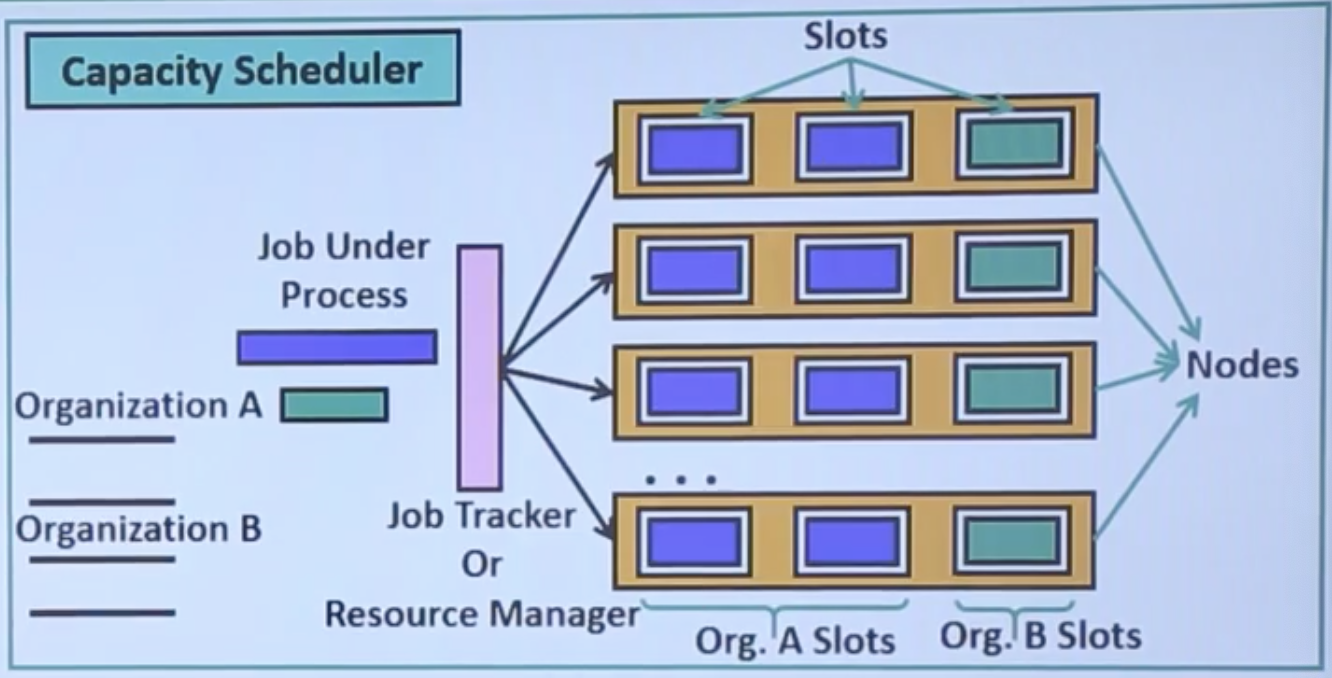
- In the Capacity Scheduler, there are multiple queues to schedule the tasks.
- For each queue, there are dedicated slots in the cluster. When no jobs are running, the task of one queue can occupy as many slots as possible
A computer cluster is a set of loosely or tightly connected computers that work together so that, in many respects, they can be viewed as a single system.
- When a new job comes in the next queue, it will replace the jobs from those slots which are dedicated to that queue.
How Fair Scheduler Works?
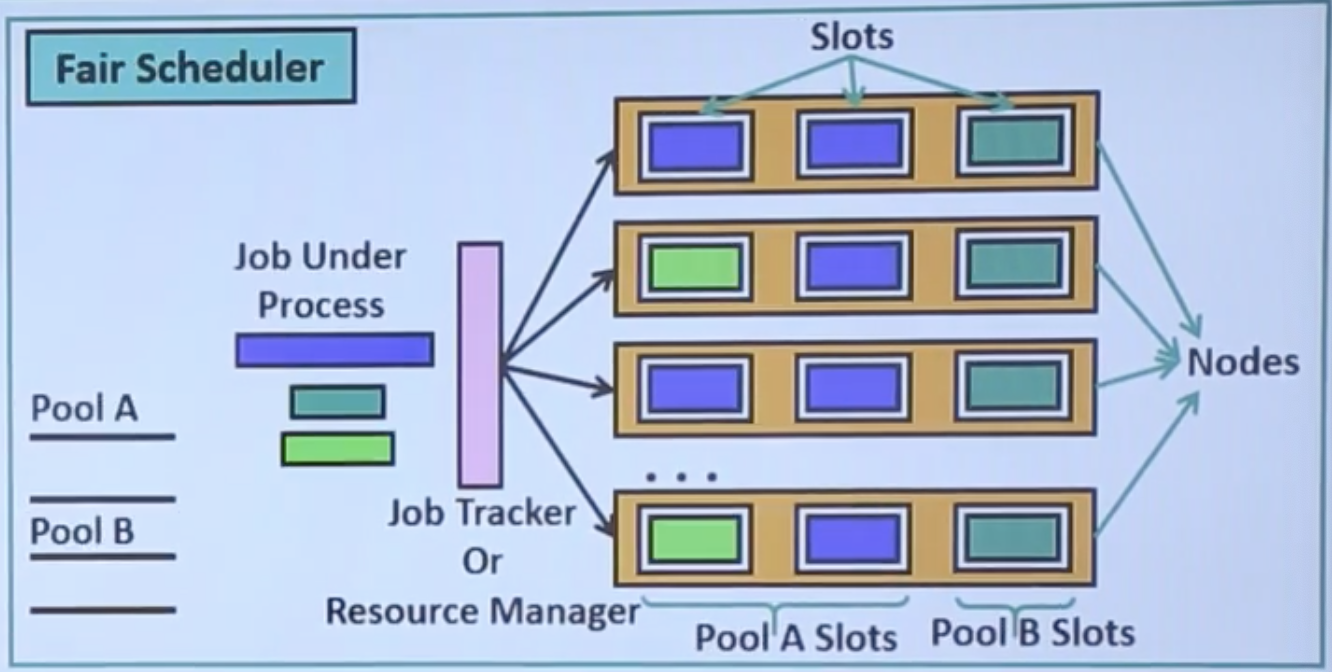
- The Fair Scheduler is very similar to the Capacity Scheduler.
- When some higher priority job comes in the same queue, it is processed in parallel by replacing some portion of the task from dedicated slots.

댓글남기기