
[Hadoop] Overview on HDFS
What is HDFS?
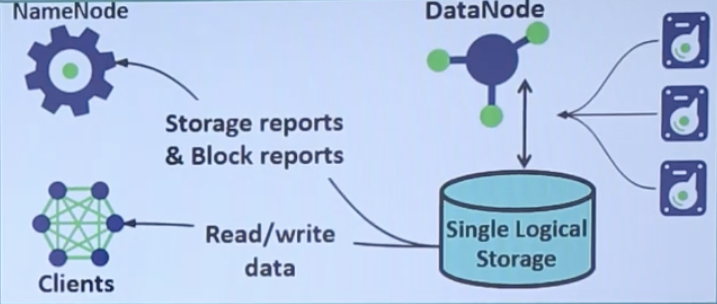
- Hadoop comes with a distributed file system called Hadoop Distributed File System or HDFS. Using the HDFS, the main data is stored in multiple data nodes, and also replicated. When one data node is down, the data can be accessed through any other data node which contains the replication.
- HDFS is very cost effective as it uses very simple commodity hardware to process and store data blocks.
Concept of HDFS:
- Data Blocks: The data blocks are the minimum size of data that can be read or write in one shot. The default size of the HDFS block is 128MB. The block size is changeable. The data are divided into different blocks and stored in the clusters. When the data size is smaller than the block size, then it will not occupy the whole block.
- NameNode: The NameNode is like the master node in the HDFS. It is like a controller or the manager of the HDfS. NameNode does not store the data in it, but it stores the metadata of all files.
- DataNode: These nodes are like the worker nodes of HDFS. These stores the data blocks. DataNodes report back different information about the data blocks like a list of data they are storing etc. to the name node periodically.
- DataNodes are generally the commodity hardware. They also create blocks, create replication or delete data blocks as stated by the NameNode.
Advantages and Disadvantages of HDFS:
- Advatages:
- We can use HDFS to store large data like hundreds of Megabytes or Gigabytes.
- HDFS is designed for write-once and read many-times pattern. So it has the streaming data access facility.
- As it works on low-cost commodity hardware, so this is cost effective model.
- Disadvantages:
- The data accessing speed for HDFS is really slow. When we need to access data in very less time, HDFS is not so helpful there.
- If we store the small size of data into the HDFS it may take lots of space in the Name-Node. As the Name-Node stores meta information about the files.
- When we need to write the data for multiple time, it is not so helpful then. It is efficient to read multiple times but not writing.

댓글남기기