
[Hadoop] What is MapReduce?
What is MapReduce?
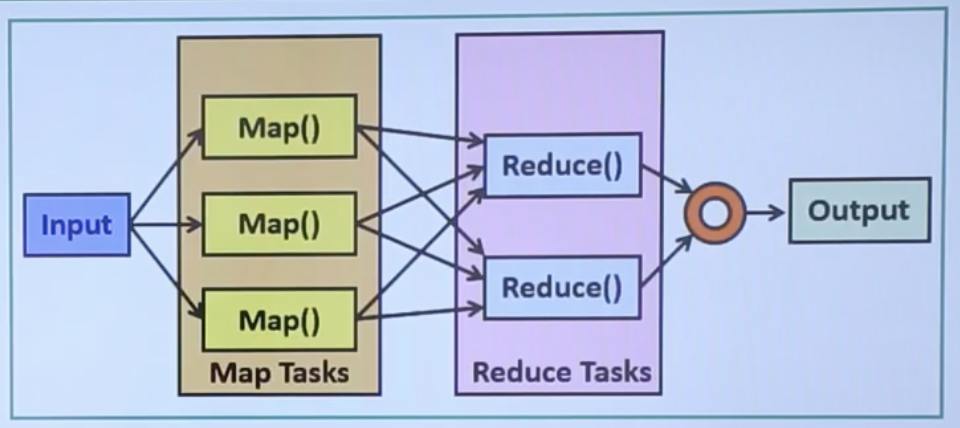
- The MapReduce is one of the main components of the Hadoop Ecosystem. MapReduce is designed to process a large amount of data in parallel by dividing the work into some smaller and independent tasks.
- The whole job is taken from the user and divided into smaller tasks, and assign them to the worker nodes. MapReduce programs take input as a list and convert to the output as a list also.
The Map Task:
- The map/mapper takes a set of keys and values. We can say it as a key-value pair as input. The data may be in a structured or unstructured form. The framework can make into keys and values.
- The keys are the reference of input files, and Values are the dataset.
- The user can create a custom buisness logic based on their need for data processing.
- The task is applied on every input value.
The Reduce Task:
- The Reducer takes the key-value pair, which is created by the mapper as input. The key-value pairs are sorted by the key elements.
- In the reducer, we perform the sorting, aggregation or sumation type jobs.
How MapReduce task works?
- The given inputs are processed by the user-defined methods. All different business logics are working on the mapper section. Mapper generates intermediate data and reducer takes them as input. The data are processed by user-defined function in the reducer section. The final output is stored in HDFS.
The Operation of MapReduce Task:

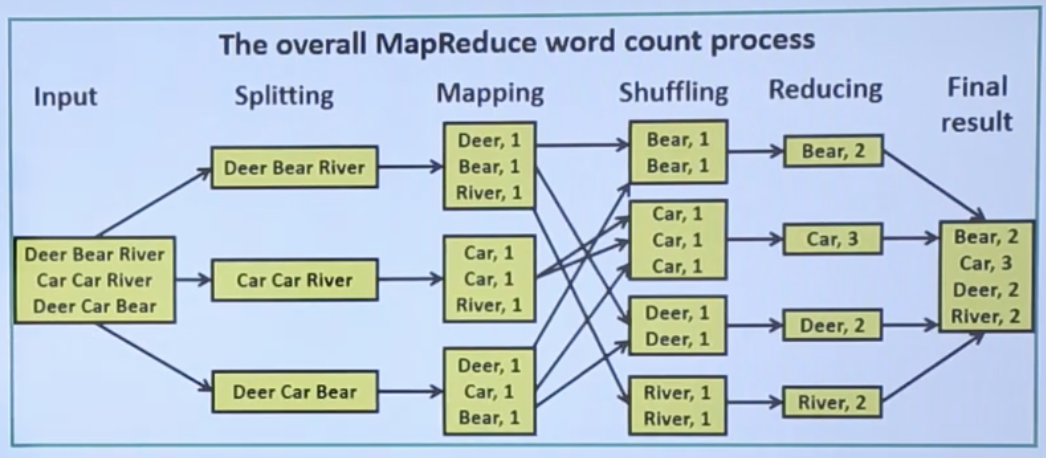
- The pictorial representation on how the MapReduce task works.

댓글남기기