
[Hadoop] Example of MapReduce Program
The practical demonstration of WordCount Problem:
- To run a MapReduce Program, we need to start Hadop demons first.
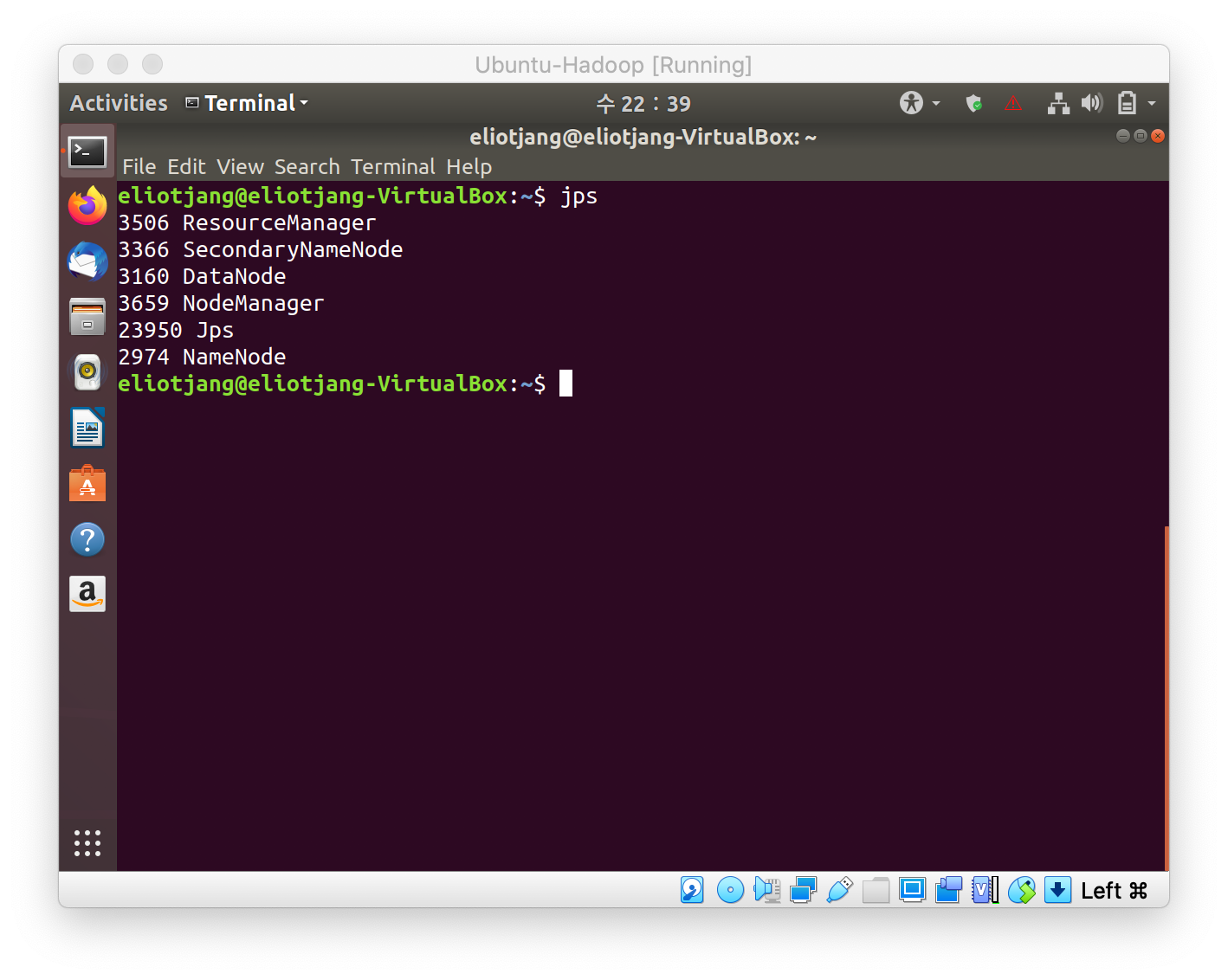
- Make temp folder and file.
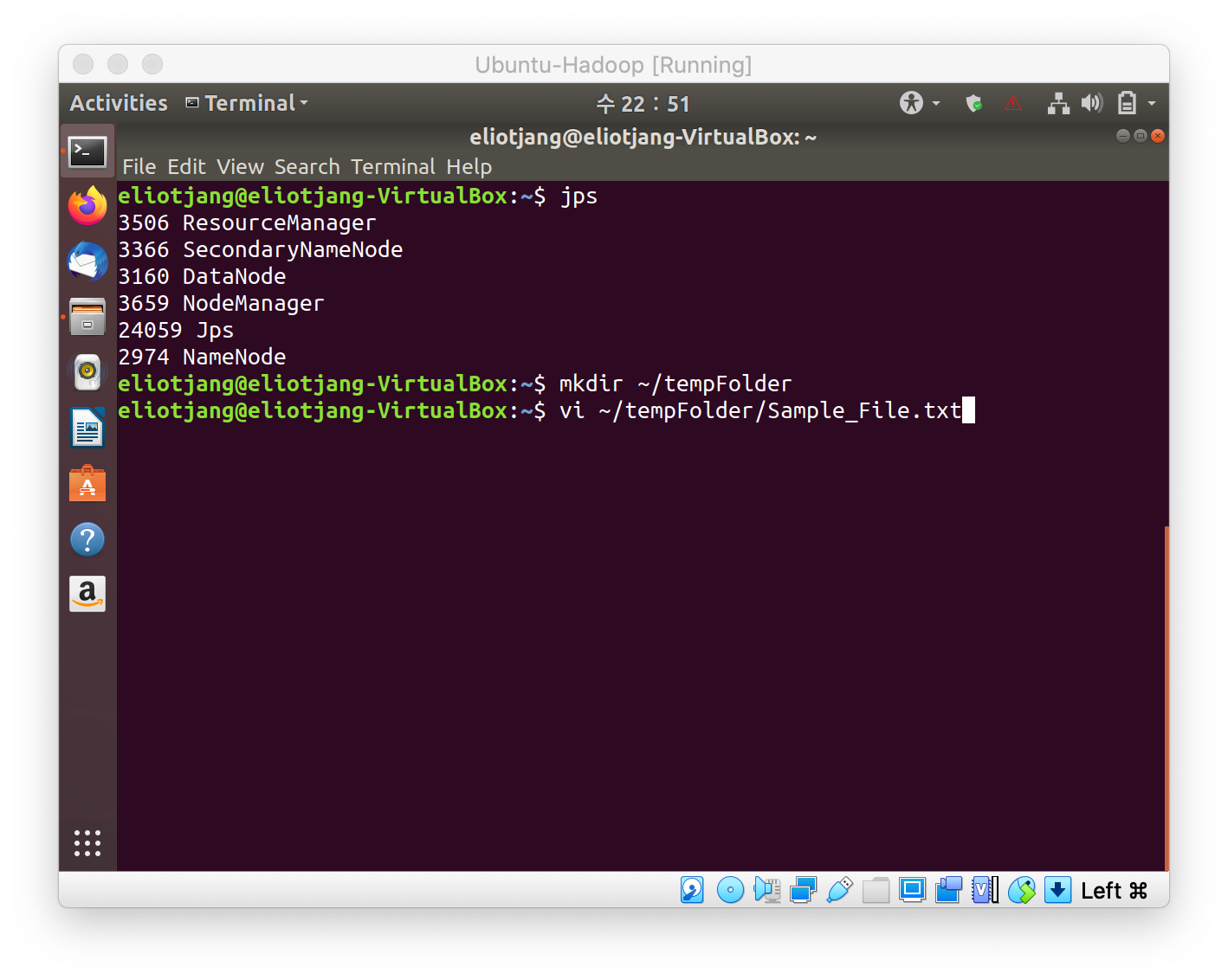
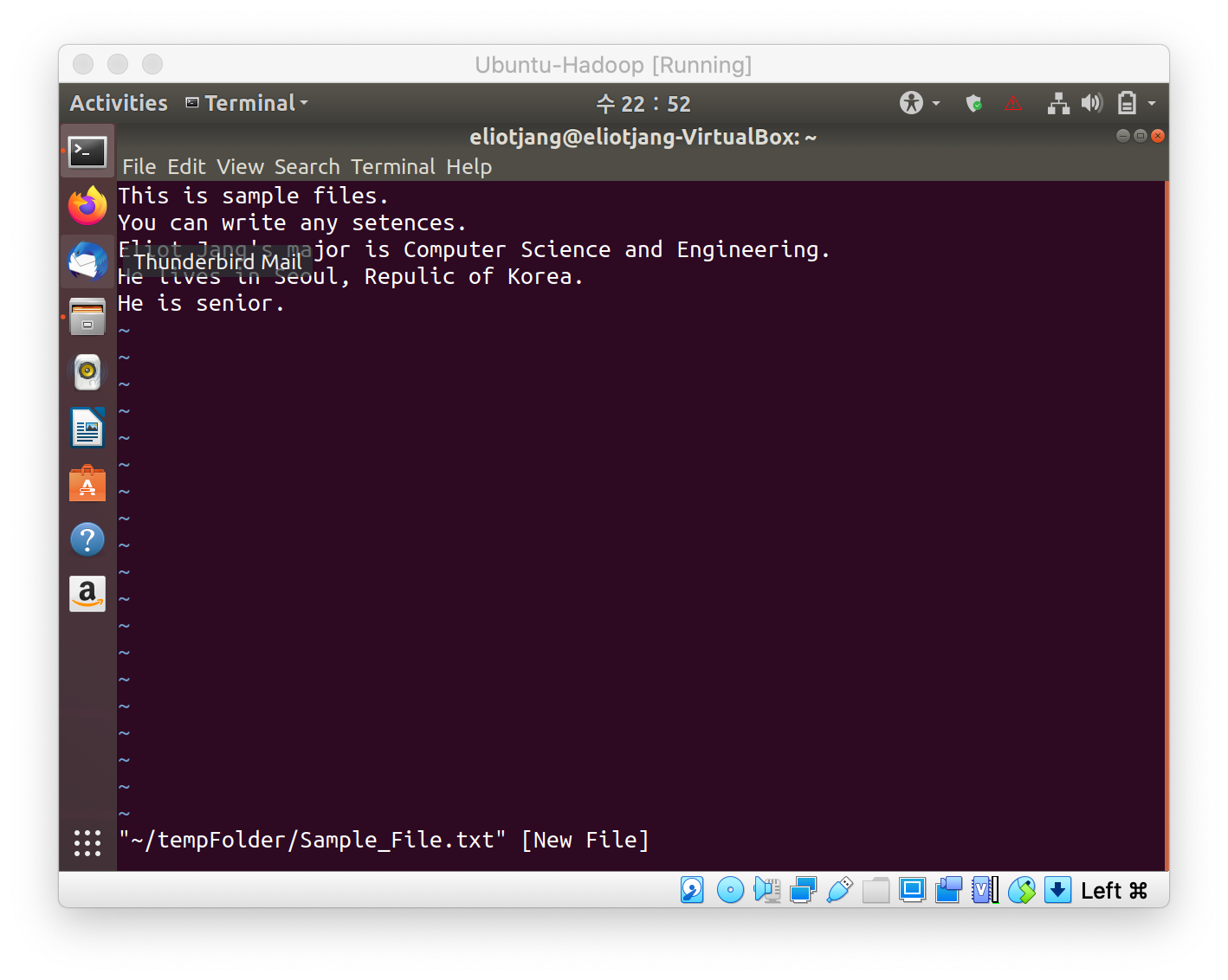
- Create and copy a file into HDFS. Put the file inside a separate directory. In this case, it is /input
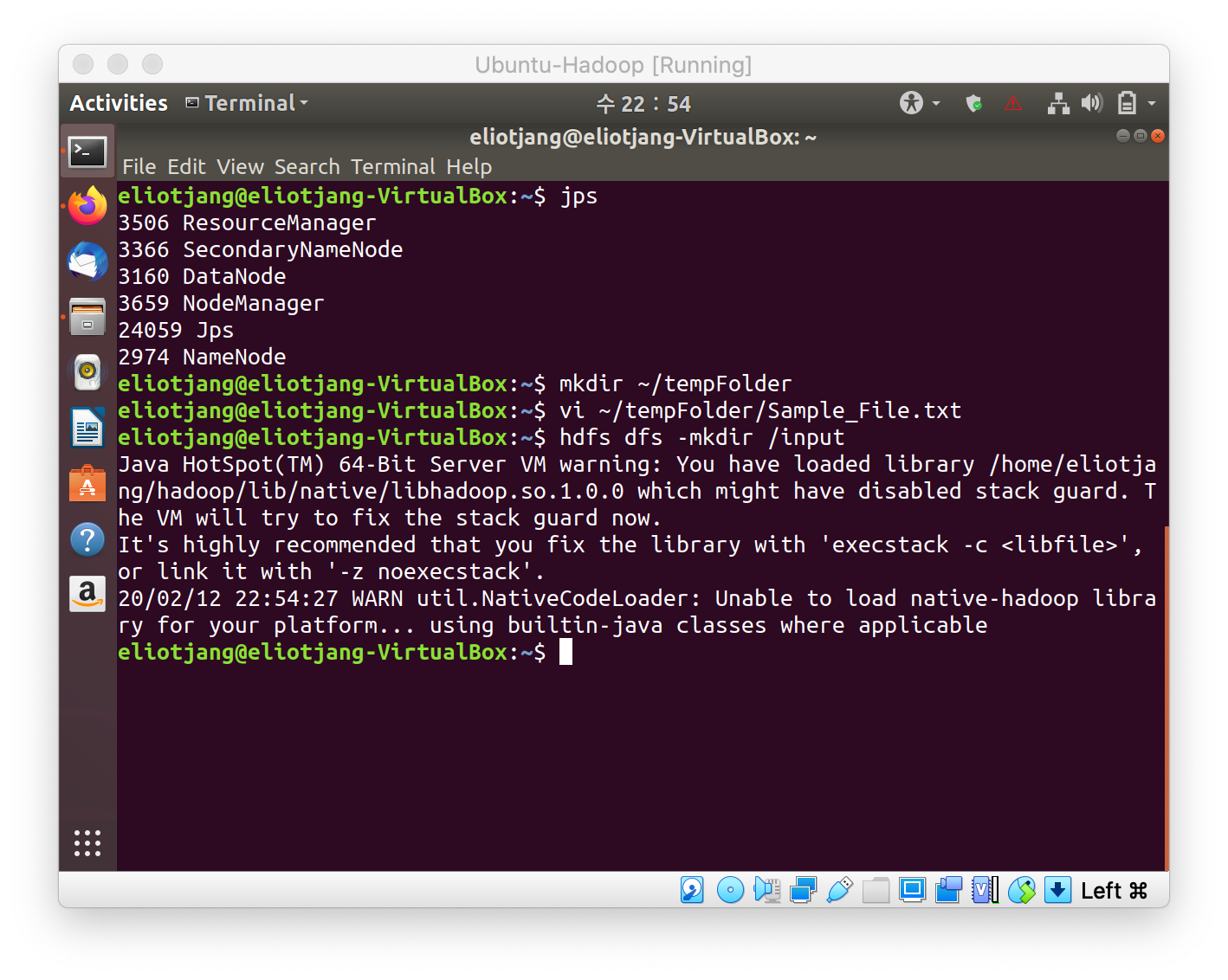
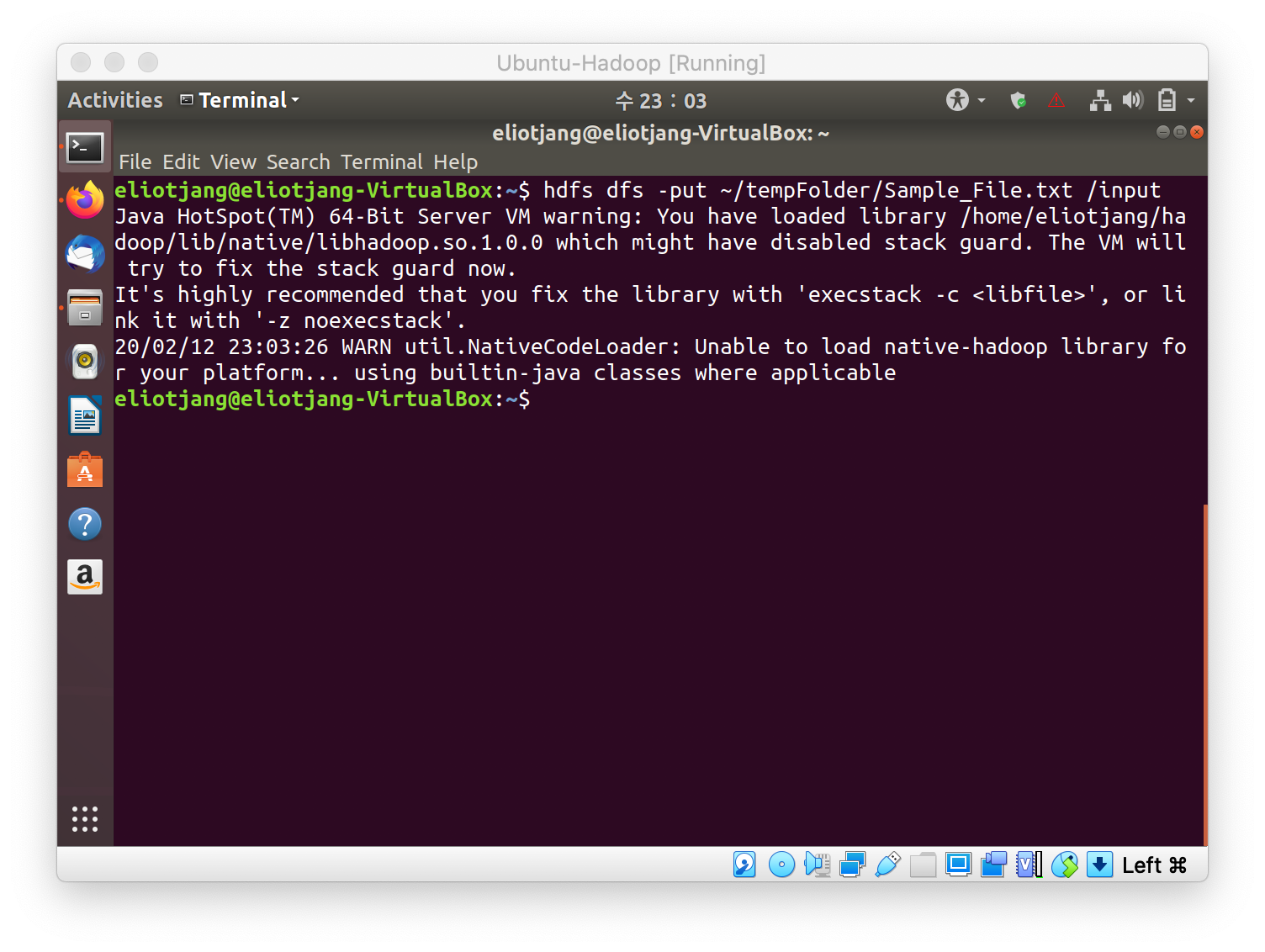
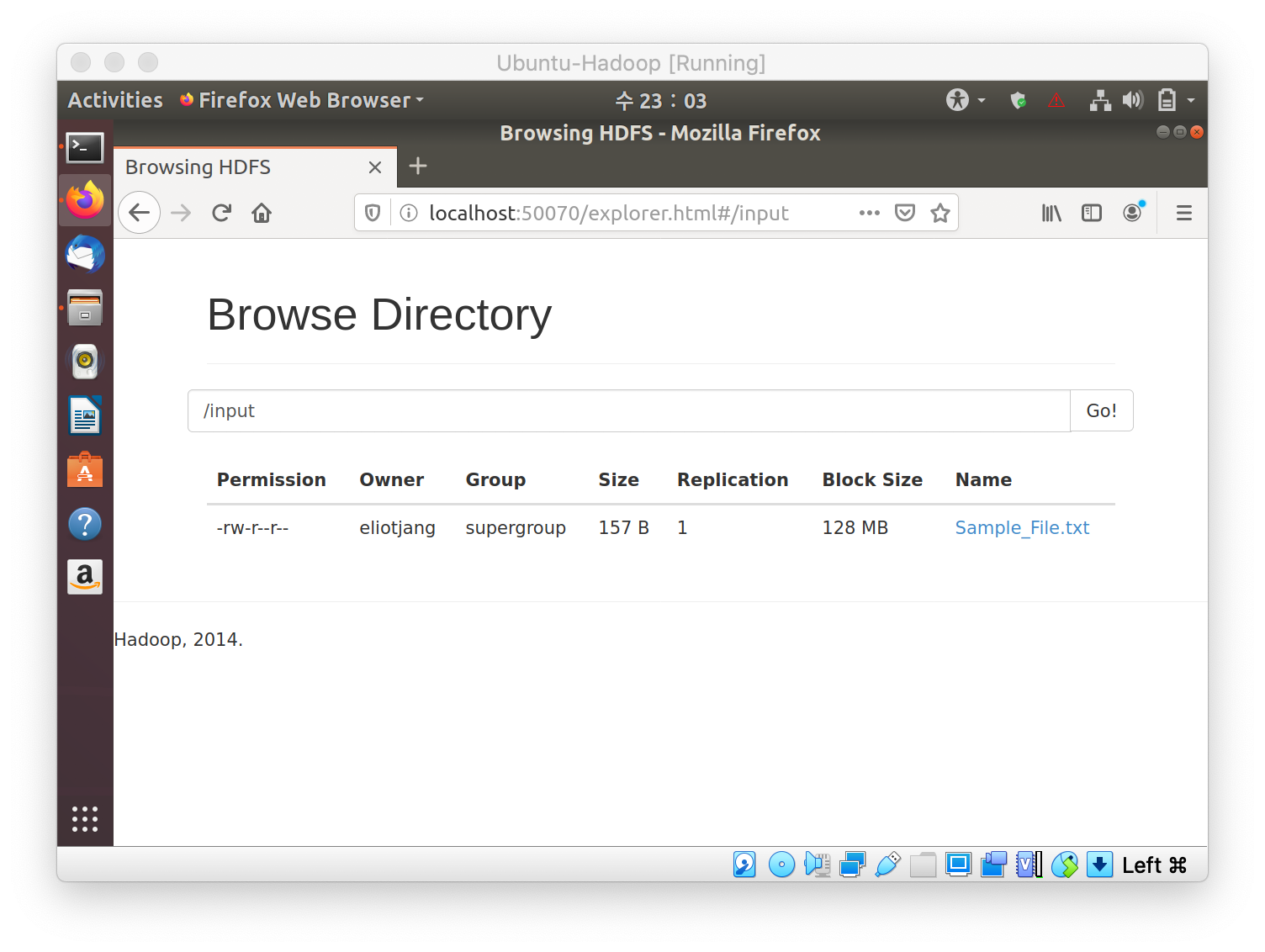
-
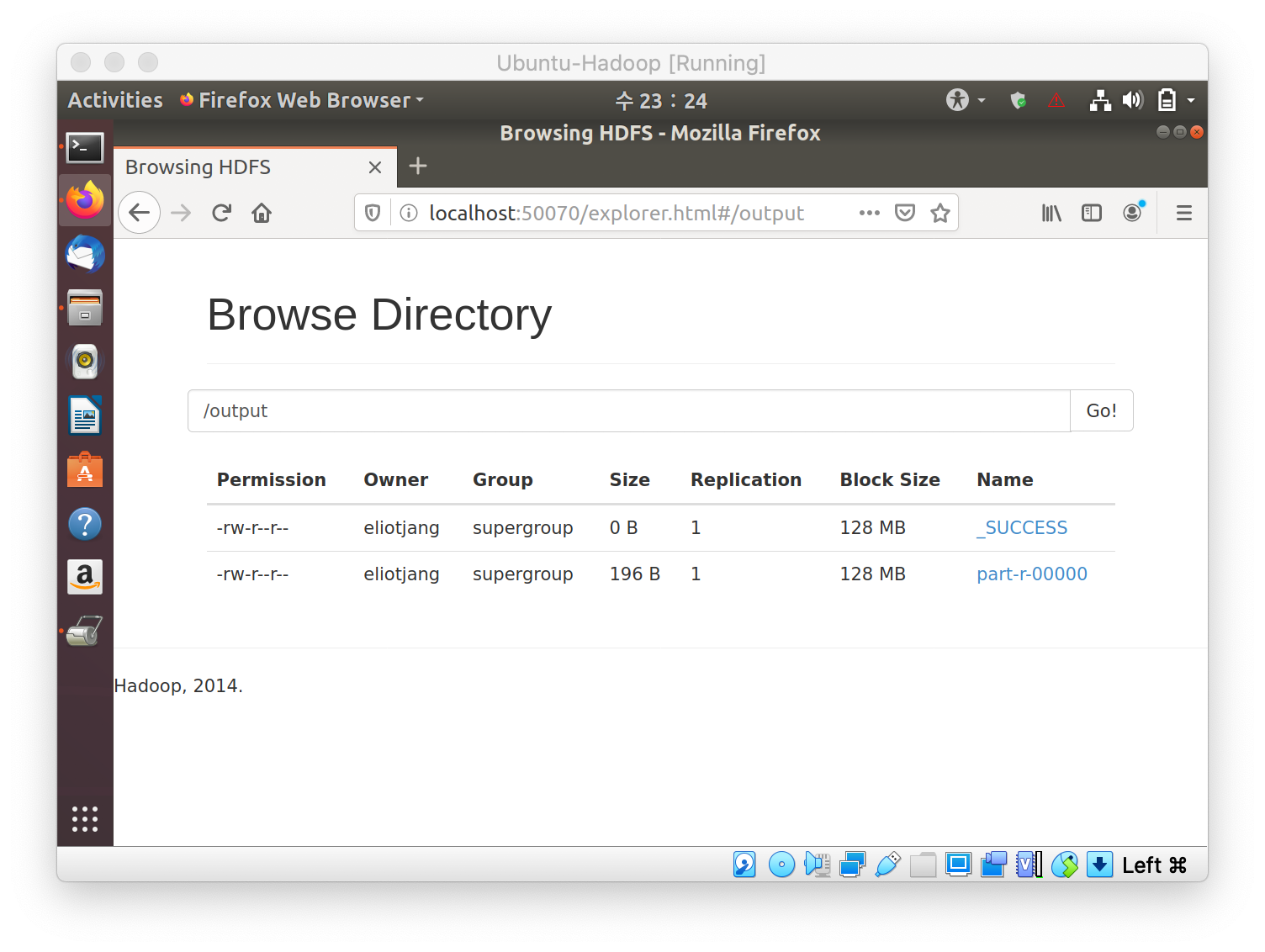
The MapReduce will create another directory, in this case it is /output. In that directory there will be a part file. That file will hold the final MapReduce output.
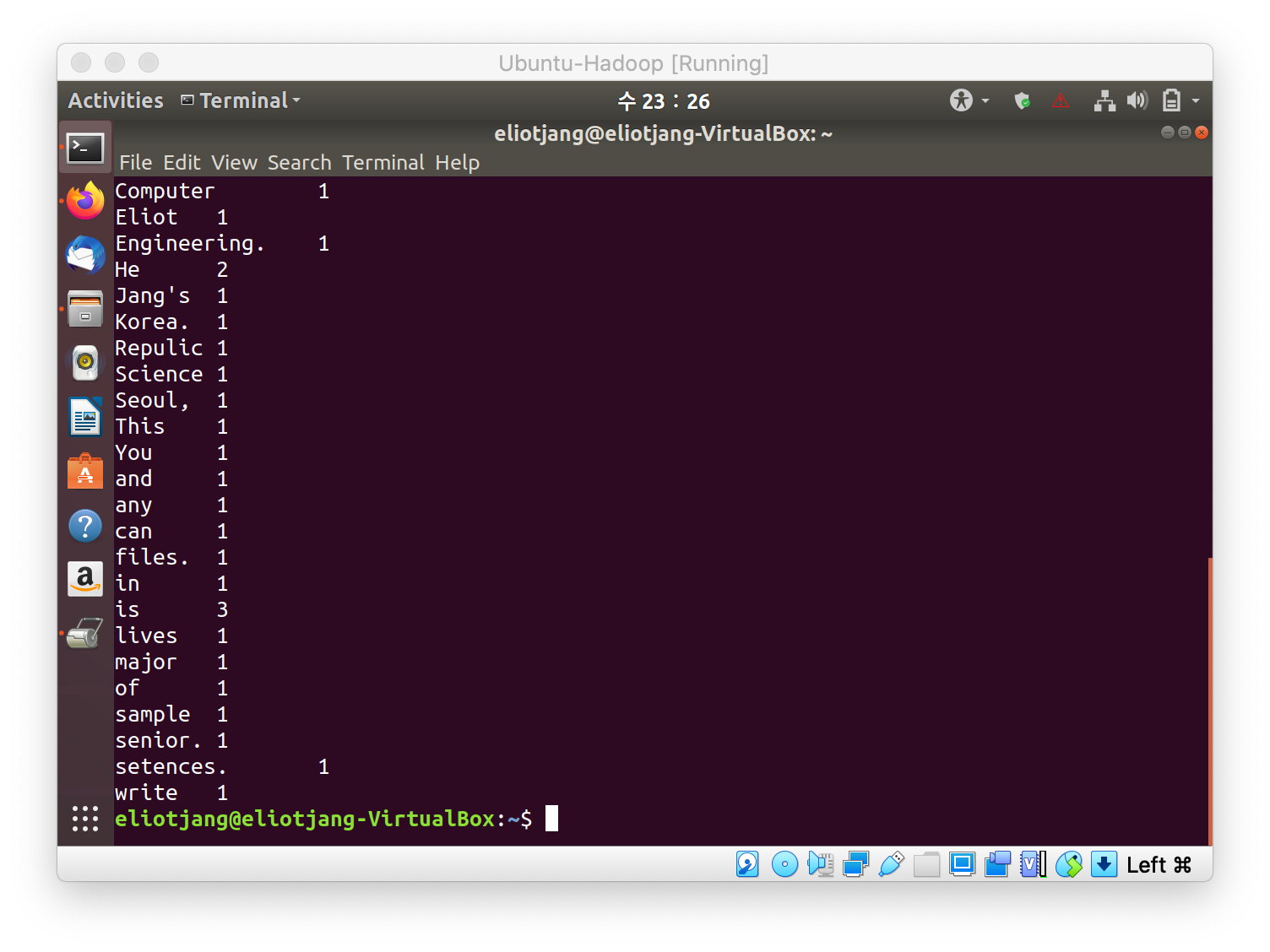
- The WordCount program is one of the default programs, that comes with Hadoop. We can use the jar file to execute the MapReduce Task.
- The syntax of using the Jar file to start MapReduce task:
$ hadoop jar <jar_path> <class_name> <parameters>
- In this case the parameters are the input and output directory.




댓글남기기